Young Executive Academy’nin 10. haftasında Hopi‘nin IT Direktörü Murat Taşbaş ve Semih Aşçıoğlu vardı. Murat Bey, öğrencilere Büyük Veri’nin ne olduğu, nerelerde kullanıldığı, yararları ve Büyük Veri teknolojilerinin neler olduğundan bahsettikten sonra Semih Bey, Hopi’de verilerin nasıl kullanıldığını anlattı ve birlikte öğrencilerin sorularını cevapladılar. Kendilerine YEA Ailesi olarak çok teşekkür ediyoruz.
Büyük Veri Nedir?

Büyük Veri, eldeki veri tabanı yönetim araçları veya geleneksel veri işleme uygulamaları kullanılarak işlenmesi zorlaşacak kadar büyük ve karmaşık veri kümeleri için kullanılan bir terimdir. Buradaki amaç, anlamlı bir sonuç elde ederek firmalar müşterilerinin davranışlarını anlayabilecek ve doğru bir şekilde değerlendirme fırsatı bulacaktır.
Büyük Veri Bileşenleri Nelerdir?

Büyük Verinin 5 tane bileşeni bulunmaktadır:
Hacim(Volume): İstenen sonuçları elde etmek için işlenen ve analiz edilen veri miktarını ifade eder.
Hız(Velocity): Veri oluşturma hızını ifade eder. Verilerin talepleri karşılamak için ne kadar hızlı üretildiği ve işlendiği, verilerdeki gerçek potansiyeli belirler.
Çeşitlilik(Variety): Depolanan, analiz edilen ve kullanılan veri türünü temsil eder.
Doğruluk(Veracity): Olası tutarlılığın büyük veri için yeterince iyi olduğunu gösterir.
Değer(Value): Depolanan verilerin kalitesiyle alakalı bir bileşendir.
Büyük Veri Nerelerde Vardır?
Alışveriş verileri, sosyal medyada bırakılan izler, hava durumu verileri, banka kartı/kredi kartı işlemleri gibi çoğu yerde birçok veri bulunmaktadır. İnsanların bir dakikada arkasında bıraktığı izleri aşağıdaki fotoğrafta görebilirsiniz. Bu fotoğraftaki veriler pandemiden önceki verileri kapsamaktadır.

Büyük Veri Uygulamaları ve Yararları Nelerdir?

Büyük Veri, suçları önlemek amacıyla dolandırıcılık gibi olaylarda, sosyal medya analizlerinde, talep tahmini ve kişiselleştirme gibi birçok alanda kullanılıyor. Örneğin, bir gıda firması hangi ürünün hangi saatte daha çok satılacağını hesaplayıp o ürünleri hazırlıyor ve müşterilere daha kısa sürede hizmet verme imkanı buluyor. Kişiselleştirmeye örnek olarak ise, bugün hepimizin kullandığı Netflix, Spotify gibi platformlarda kişiye özel öneriler yapılması sağlanıyor.
Dağıtımlı Sistemler ve Büyük Veri
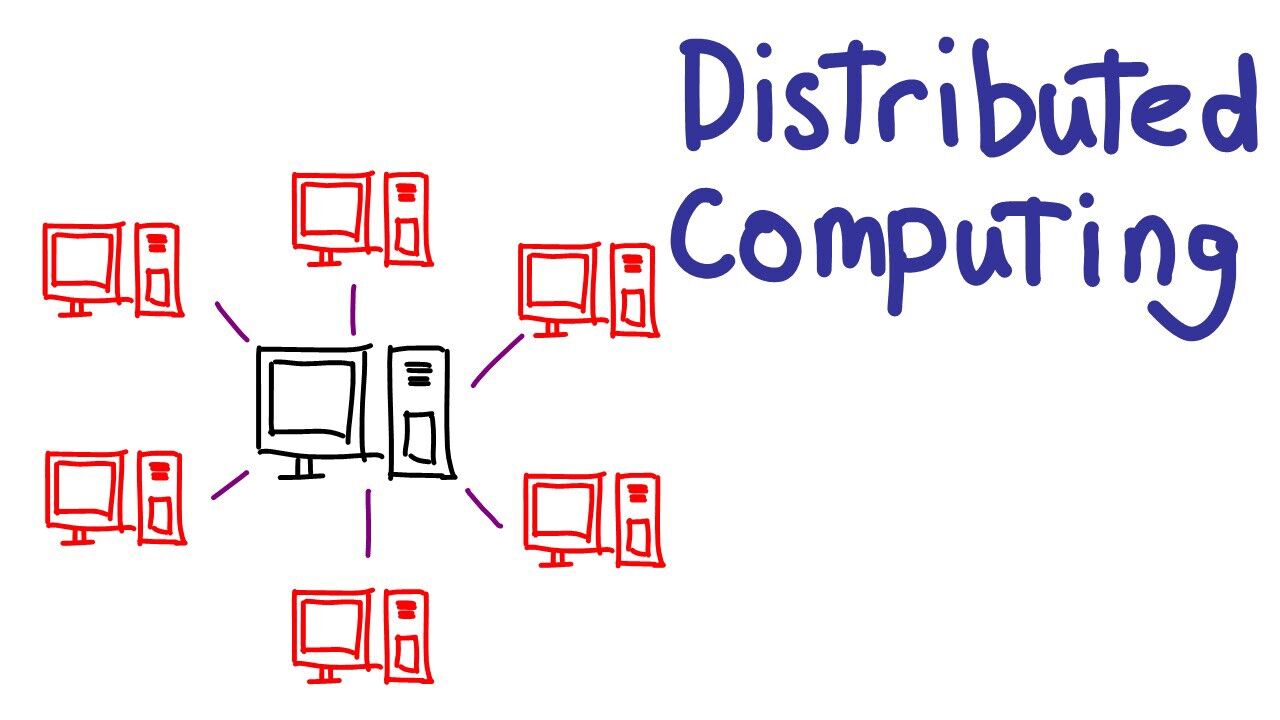
Geleneksel veri tabanlarında çok hızlı analiz yapılaması zorlaşır, çok büyük hacimlere geldiğinde problem yaşanabilir. Bunun çözümü ise verileri dağıtık sistemlerde tutmaktır. Dağıtık sistem, birden fazla otomatik bilgisayarın bir ağ üzerindeki iletişimidir. Ağdaki bilgisayarlar belirli bir hedefe ulaşmak için birbirleriyle etkileşim içerisindedirler. Örneğin, aynı makineden 10 tane yan yana koydunuz ve veriyi alırken tek elde değil, bu 10 makineye dağıtarak tuttuğunuzu düşünebilirsiniz.
Dağıtık sistemlerin en önemli fonksiyonları; eş zamanlı olabilmeleri, hesaplama hızının yüksek olabilmesi, ölçeklenebilir olması, esnek olması ve hataya toleranslı olmasıdır.
Veriyi İşlemek İçin Neler Kullanılıyor?

Apache Hadoop
Verileri dağıtık bir ortamda depolamak için tasarlanmış bir açık kaynak platformudur. Video, resim, yazı gibi her türlü veriyi tutma imkanı vardır. Ölçeklenebilir ve hataya toleranslı bir yapısı bulunmaktadır. HDFS(Hadoop Distributed File System) ve Map-Reduce olmak üzere 2 bölümden oluşur. HDFS sunucuların disklerini bir araya getirerek büyük bir sanal disk oluşturan dosyalama sistemidir. Map-Reduce ise, Hadoop’un dağıtık veri işleme modelidir ve tüm veriler merkezde olmadığı için bütün işlemler ayrı kümelerde(node) yapılır. Daha sonrasında, her kümeden cevap alınır ve sonuç oluşturulur.
Apache Spark
Hadoop’a atılan verilerin işlenmesini hızlandırmak amacıyla tasarlanan bir üründür. Dağıtık yapıda çalışır, ölçeklenebilir ve hataya toleranslıdır. Gerçek zamanlı veri işleme ve toplu işlemeyi destekler. Apache Spark’ın ana özelliği, bir uygulamanın işlem hızını artıran bellek içi küme hesaplamadır(in-memory computing).
Apache Beam
Toplu olarak bakıldığında iş ve akışları birleştiren bir programlama modelidir. DataFlow, Flink, Spark ile çalışabilir. Java, Python, Scala gibi dillerle birlikte kullanılabilir.
Apache Kafka
Apache Kafka, dağıtık bir veri akış platformudur. Veri alma tarafında büyük hacimli verileri çok hızlı işler. Ölçeklenebilir ve hataya toleranslıdır.
Apache Hive
Büyük verileri analiz etmek için kullanılan bir veri ambarı aracıdır. Hadoop gibi dağıtık dosya sistemlerinde kayıtlı olan büyük verileri sorgulamak için kullanılır.
Apache Hbase
Hataya toleranslı olan bir NoSQL çözümüdür. HDFS üzerinde real time yani anlık olarak çok büyük verileri analiz edebilir.
Cassandra
Açık kaynak ve Java ile geliştirilmiş bir NoSQL veritabanı tipidir. Ölçeklenebilir ve hataya dayanıklı bir yapısı vardır. Dağıtık, merkezi olmayan bir mimariye sahiptir.
HOPİ’de Büyük Veri Mimarisi
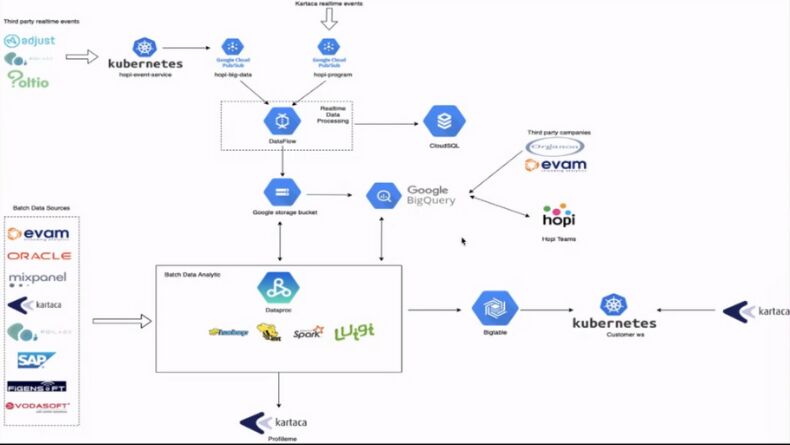
Hopi, 2015 yılında kurulan kişiselleştirilmiş alışveriş deneyimi sunan bir mobil uygulamadır. Alışveriş alışkanlıklarına göre kişiyi tanır, zevklerine ve ilgi alanlarına göre kişiye özel kampanyalar sunar. İlerleyen zamanlarda HopiShop ve HopiPay kullanıcılara sunulacak. Hopi’de verilerin nasıl kullanıldığını ise aşağıdaki şemada görebilirsiniz.
Geleceğin yönetici adaylarının 6 ay boyunca 5 farklı konuda 120 farklı şirketlerin buluştuğu Young Executive Academy’nin ikinci dönem başvuruları başladı. Programa başvurmak için buraya tıklayabilirsiniz.
Önceki YEA içeriklerimize de ilginizi çekebilir:
YEA Big Data YEA Big Data Emre Tuna Aydın – Power BI ile İş Zekası Rapor Tasarımı ve Uygulaması
YEA Big Data Sibel Bilge Sonuç: İleri Veri Okuryazarlığı
Özgün İçerik

{kind=link}